(데이터분석)파이썬, Python_타이타닉 데이터셋 전처리 하기
목차
kaggle에 있는 타이타닉 데이터셋을 Seaborn에 내장된 타이타닉 데이터셋 처럼 전처리를 하고자 한다.
https://www.kaggle.com/competitions/titanic/overview
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
데이터 확인하기
- kaggle Titanic dataset (Train)

- seaborn Titanic dataset

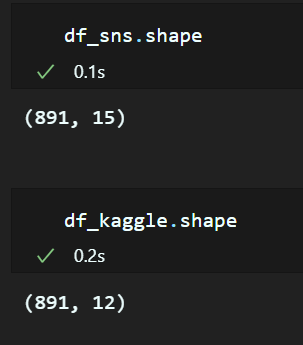
- shape
- null 값
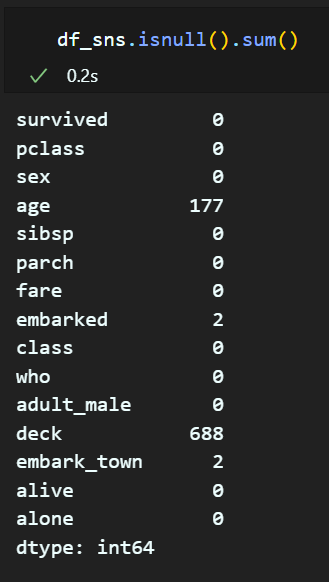

우선 컬럼을 비교해보자면, kaggle 데이터셋에는 'class', 'who', 'adult_male', 'deck', 'embark_town', 'alive', 'alone' 컬럼이 없고, 'PassengerId', 'Name', 'Cabin', 'Ticket' 컬럼이 더 있다는 것을 알 수 있다.
때문에, ['class', 'who', 'adult_male', 'deck', 'embark_town', 'alive', 'alone' ] 순서대로 컬럼을 생성하고 마지막에 ['PassengerId', 'Name', 'Cabin', 'Ticket'] 컬럼을 삭제한 후 컬럼명을 Seaborn 데이터셋 컬럼명처럼 모두 소문자로 바꿀 계획이다.
데이터 전처리
1. 'class' 생성
pclass가 1 이면 First, 2 이면 Second, 3 이면 Third
df_kaggle['class'] = 'First'
df_kaggle.loc[df_kaggle['Pclass'] == 2, 'class'] = 'Second'
df_kaggle.loc[df_kaggle['Pclass'] == 3, 'class'] = 'Third'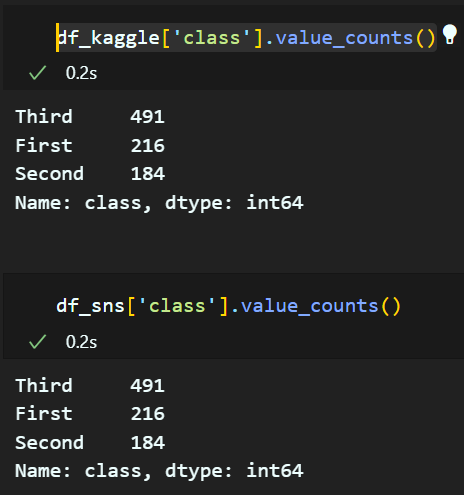
2. 'who' 생성
16세 미만이면 'child', 16세 이상이면서 male이면 man, 16세 이상이면서 female이면 woman
단, age 가 null 값이면 성인이다.
df_kaggle['who'] = 'man'
df_kaggle.loc[df_kaggle['Sex'] == 'female', 'who'] = 'woman'
df_kaggle.loc[df_kaggle['Age'] < 16, 'who'] = 'child'
3. 'adult_male' 생성
16세 이상이면서 male이면 True, 아니면 False
단, age 가 null 값이면 성인이므로 male 이면서 age가 null 이면 True
df_kaggle['adult_male'] = False
df_kaggle.loc[(df_kaggle['Sex'] == 'male')&(df_kaggle['Age'] >= 16), 'adult_male'] = True
df_kaggle.loc[(df_kaggle['Sex'] == 'male')&(df_kaggle['Age'].isnull()), 'adult_male'] = True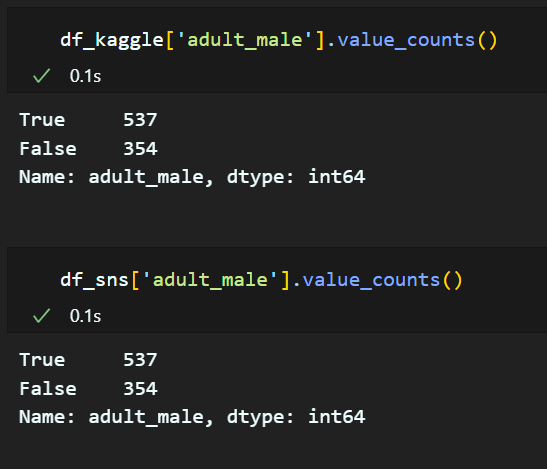
4. 'deck' 생성

위의 사진에서 보면, 'deck' 컬럼은 'Cabin' 컬럼의 앞글자만 따서 추출한 컬럼임을 알 수 있다.
여기에서 생각해봐야 하는 것은 두 컬럼의 null 값이 한 개가 차이가 난다는 것인데 ('deck':688, 'Cabin':687)
두 컬럼의 유니크값을 살펴보면 'Cabin'에는 'T'라는 값이 존재하지만 'deck'에는 'T'가 없음을 알 수 있다.
그러므로, 'T' 값을 null로 처리해야 한다.
df_kaggle['deck'] = df_kaggle['Cabin']
df_kaggle['deck'] = df_kaggle.loc[df_kaggle['deck'].notnull(), 'deck'].apply(lambda x: x[:1])
df_kaggle.loc[df_kaggle['deck'] == 'T', 'deck'] = np.NaN
5. 'embark_town' 생성
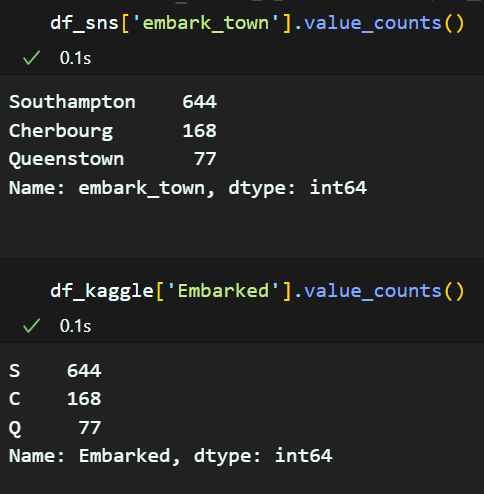
'데이터확인하기'에서 'embark_town'과 'Embarked'의 null 값의 개수가 같으므로 두 컬럼의 value count 를 확인해본 결과, 그 수가 일치하는 것을 알 수 있었다. 그러므로, 'Embarked' 가 S면 Southamton, C이면 Cherbourg, Q이면 Queenstown 으로 설정하여 컬럼을 생성하면 된다.
df_kaggle['embark_town'] = np.NaN
df_kaggle.loc[df_kaggle['Embarked'] == 'S', 'embark_town'] = 'Southampton'
df_kaggle.loc[df_kaggle['Embarked'] == 'C', 'embark_town'] = 'Cherbourg'
df_kaggle.loc[df_kaggle['Embarked'] == 'Q', 'embark_town'] = 'Queenstown'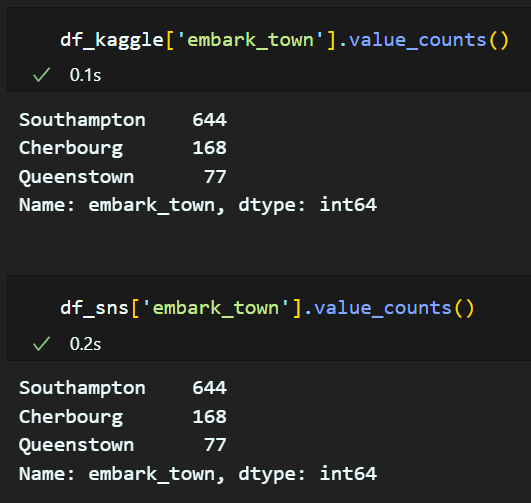
6. 'alive' 생성
'Survived'가 0 이면 no, 1이면 yes
df_kaggle['alive'] = 'no'
df_kaggle.loc[df_kaggle['Survived'] == 1, 'alive'] = 'yes'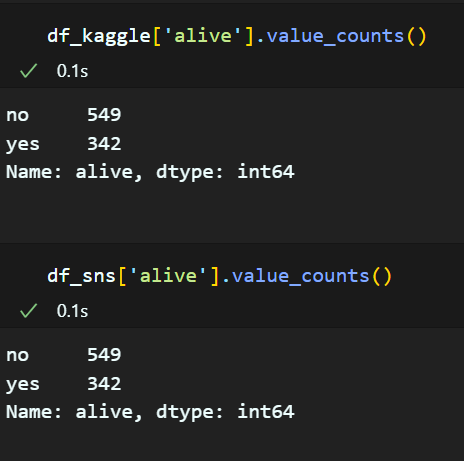
7. 'alone' 생성
'Sibsp', 'Parch'가 둘 다 0 이면 True, 아니면 False
df_kaggle['alone'] = False
df_kaggle.loc[(df_kaggle['SibSp'] == 0)&(df_kaggle['Parch'] == 0), 'alone'] = True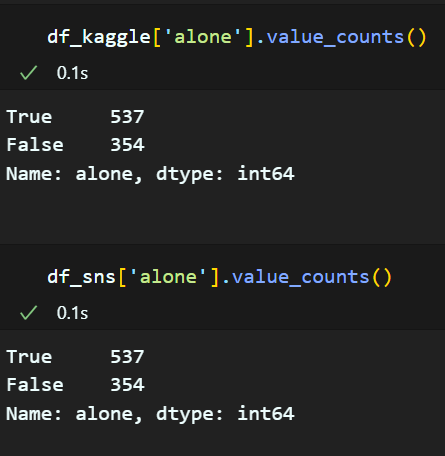
8. 'PassengerId', 'Name', 'Cabin', 'Ticket' 컬럼 삭제
df_kaggle.drop(columns=['PassengerId', 'Name', 'Ticket', 'Cabin'], inplace=True)
9. 컬럼명 소문자 변환
col_lst = []
for col in df_kaggle.columns:
col_lst.append(col.lower())
df_kaggle.columns = col_lst
10. 확인
