(머신러닝)타이타닉 데이터 셋으로 보는 Classification(분류)_4. 나이브 베이즈
목차
0. 나이브베이즈
나이브 베이즈란 데이터가 각 클래스에 속할 특징 확률을 계산하는 조건부 확률 기반의 분류 방법으로, 나이브 베이즈에서의 나이브는 모든 변수(feature)들이 동등하다는 것을 의미하며, 베이즈는 입력 특징(입력변수)이 클래스 전체의 확률 분포 대비 특정 클래스에 속할 확률을 베이즈 정리를 기반으로 계산한다는 것을 뜻한다.
쉽게 설명하자면, 사건 B가 주어졌을 때 사건 A가 일어날 확률인 P(A|B)라는 조건부 확률을 사용한 분류기인 것이다.
결국 나이브 베이즈는 베이즈 정리를 기반으로 주어진 Input에 대한 Output의 확률을 예측하는 것인데, 베이즈 정리는 다음과 같다.
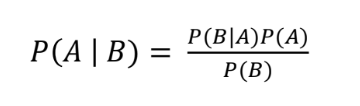
이러한 베이즈 정리를 기반으로 만든 나이브 베이즈 알고리즘의 수식은 다음과 같은데 Input인 x 들이 Output인 y일 확률을 예측하기 위해, y 일때의 x의 확률과 전체 중의 y의 확률을 모두 곱한 것이다.

https://scikit-learn.org/stable/modules/naive_bayes.html
1.9. Naive Bayes
Naive Bayes methods are a set of supervised learning algorithms based on applying Bayes’ theorem with the “naive” assumption of conditional independence between every pair of features given the val...
scikit-learn.org
수식으로만 보면 어려우니 타이타닉 데이터 셋으로 직접 나이브베이즈 알고리즘을 실습해보자.

먼저, Input: 성별=Male, 선실등급=First 일때는 다음과 같으므로 4/6 * 2/6 * 6/10 = 2/15이다.
P (생존 = 0 | 성별 = Male, 선실등급 = First) ∝ P(성별 = Male | 생존 = 0) P(선실등급 = First | 생존 = 0) P(생존 = 0)
-----
First, Male이 생존하지 않을 확률 = male 4/생존(0) 6 * first 4/생존(0)6 * 생존(0)6/전체 10
1. Modeling
- feature: ['Pclass', 'Sex_num']
from sklearn.naive_bayes import CategoricalNB
import pandas as pd
X_train = train_data[['Pclass', 'Sex_num']]
# 나이브베이즈 생성: 범주형으로 분류해야하기 때문에 CategoricalNB를 사용
cat_nb = CategoricalNB()
# 학습
cat_nb.fit(X_train, y_train)
# 예측
y_pred = cat_nb.predict(X_train)
# 평가
accuracy_score(y_train, y_pred)
# 0.7867564534231201
# test set으로 예측하여 평가하기
X_test = test_data[['Pclass', 'Sex_num']]
model = cat_nb.predict(X_test)
cat_nb_model = pd.DataFrame()
cat_nb_model['PassengerId'] = test_data['PassengerId']
cat_nb_model['Survived'] = model
cat_nb_model.to_csv('data/cat_nb.csv', index=False)=> 0.76555