
반응형
목차
0. Overview
Kaggle에 있는 Titanic Dataset으로 머신러닝의 기초인 Classification에 대해 알아보고자 한다.
Classification 이란 데이터들을 카테고리로 나눠서 어디에 속하는지 분류하는 것이다. 이 데이터셋에서의 타겟변수(예측변수)는 Survived로, 탑승자의 생존 여부를 0(생존)과 1(생존X)로 분류하기 때문에 Classification을 사용하여 탑승자의 생존 여부를 예측해야 한다.
https://www.kaggle.com/competitions/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
1. Bussiness Understanding
- 생존자 예측
2. Data Understanding
import pandas as pd
train_data = pd.read_csv('train.csv')
train_data.shape
# (891, 12)
# 1. Null 값 확인
train_data.info()
# Age, Cabin
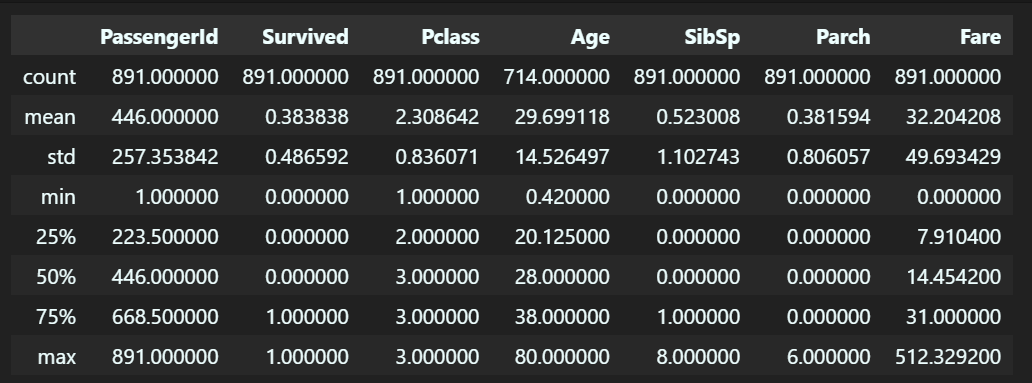
# 2. 이상치 확인
train_data.describe()
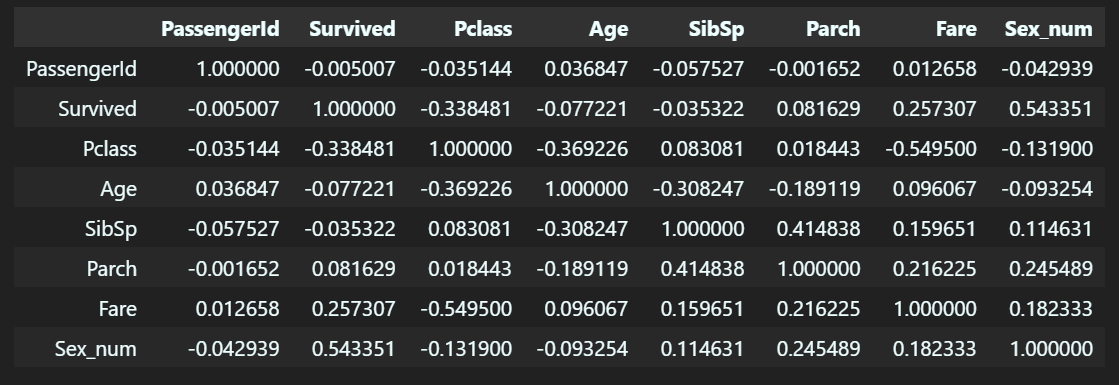
# 3. 상관계수 확인
# 상관계수 확인을 위한 Age 컬럼 One-hot encoding
train_data['Sex_num'] = train_data['Sex'].map({'male': 0, 'female': 1}) # 남 == 0, 여 == 1
train_data.corr(numeric_only=True)
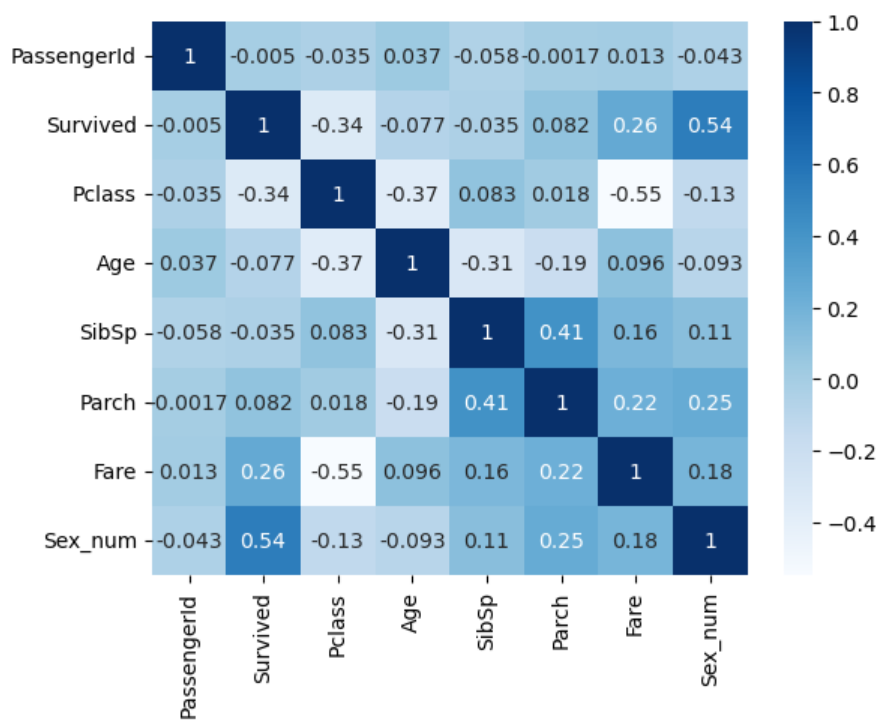
# 4. 히트맵 확인
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(train_data.corr(numeric_only=True), cmap='Blues', annot=True)
3. Data Preparation
# Age 결측치 처리
# train_data의 나이의 결측치에 나이의 평균 값 대입
train_data_age_mean = train_data['Age'].mean() # 29.69911764705882
train_data['Age'].fillna(train_data_age_mean, inplace=True)
4. Modeling
- 머신러닝 모델 사용 없이 Rule-Based 규칙 기반으로 모델 만들어보기
# model1 : 여성이면 생존
def model1(df):
df['Pred'] = 0 # 생존x 0
df.loc[df['Sex'] == 'female', ['Pred']] = 1 # 생존 1
return df['Pred']
# model2 : 여성 이거나(or) 나이가 16세 미만이면서 pclass가 2이면 생존
def model2(df):
# Dataframe 입력 받음
df['Pred'] = 0
df.loc[(df['Sex'] == 'female') | ((df['Age'] < 16) & (df['Pclass'] == 2)), ['Pred']] = 1
return df['Pred']
# model3 : 여성 이면서 pclass가 1 또는 2 이거나(or) 16세 미만이면서 pclass가 2이거나 남성이면서 pclass가 1이면 생존
def model3(df):
df['Pred'] = 0
df.loc[((df['Sex'] == 'female') & (df['Pclass'] != 3)) | ((df['Age'] < 16) & (df['Pclass'] == 2)) | ((df['Sex'] == 'male') & (df['Pclass'] == 1)), ['Pred']] = 1
return df['Pred']
5-1. Evaluate
# 정확도 함수 생성
def evaluate(label, pred):
return(label == pred).mean()
evaluate(train_data['Survived'], model1(train_data))
# 0.7867564534231201
evaluate(train_data['Survived'], model2(train_data))
# 0.7968574635241302
evaluate(train_data['Survived'], model3(train_data))
# 0.7609427609427609=> model2의 정확도가 가장 높다
5-2. Test set에 대한 평가
- 모델은 Train set으로 학습시켜 만든 모델이기 때문에 Test set에 대한 평가는 Train set에 대한 평가보다 신뢰성이 높은 평가이다.
test_data = pd.read_csv('test.csv')
# Age의 Null 값을 train의 평균으로 채워야 한다.
# 왜냐하면, train의 데이터의 양이 더 많으므로 평균치가 더 적합하기 때문이다.
test_data['Age'] = test_data['Age'].fillna(train_data['Age'].mean())
# model1
test_data['Survived'] = model1(test_data)
model1_df = test_data[['PassengerId', 'Survived']]
model1_df.to_csv('result/rule_based_1.csv', index=False)
# 0.76555
# model2
test_data['Survived'] = model2(test_data)
model2_df = test_data[['PassengerId', 'Survived']]
model2_df.to_csv('result/rule_based_2.csv', index=False)
# 0.76794
# model3
test_data['Survived'] = model3(test_data)
model3_df = test_data[['PassengerId', 'Survived']]
model3_df.to_csv('result/rule_based_3.csv', index=False)
# 0.7177=> model2의 정확도가 가장 높다.
'Python > 머신러닝-딥러닝' 카테고리의 다른 글
| (머신러닝)비지도학습_PCA를 활용한 이상치탐지 (0) | 2023.06.11 |
|---|---|
| (머신러닝)타이타닉 데이터 셋으로 보는 Classification(분류)_4. 나이브 베이즈 (0) | 2023.06.06 |
| (머신러닝)타이타닉 데이터 셋으로 보는 Classification(분류)_3. KNN (K-최근접 이웃) (0) | 2023.06.06 |
| (머신러닝)타이타닉 데이터 셋으로 보는 Classification(분류)_2. 로지스틱 회귀(Logistic Regression) (0) | 2023.06.06 |




댓글