
목차
모든 데이터가 준비되었으니 협업 필터링 추천 모델을 만들어보도록 하자.
이번 프로젝트 첫 포스팅에서 설명했던대로, Matrix Factorization을 사용하여 협업 필터링(CF) 모델을 생성하여 저장할 것 이고, 빠른 진행을 위해 VScode가 아닌 구글 코랩에서 진행하였다. (구글 코랩에서는 GPU를 사용할 수 있다.)
1. Data Load
먼저, 내 구글 드라이브에 csv 파일을 올려놨기 때문에 드라이브 마운트를 진행해서 연동 후 데이터를 가져와서 train set과 test set으로 분리해보자.
# 드라이브 마운트
from google.colab import drive
drive.mount('/gdrive')
# Data Load
movies = pd.read_csv('/gdrive/MyDrive/playdata/movie_recommendation/data/movies.csv')
movies.head(2)
users = pd.read_csv('/gdrive/MyDrive/playdata/movie_recommendation/data/users.csv')
users.head(2)
ratings = pd.read_csv('/gdrive/MyDrive/playdata/movie_recommendation/data/ratings.csv')
ratings.head(2)
# df를 train/test set으로 분할하는 함수 생성
# Args: df, holdoyt_fraction(분할 비율)
def split_dataframe(df, holdout_fraction=0.1):
test = df.sample(frac=holdout_fraction, replace=False)
train = df[~df.index.isin(test.index)]
return train, test
# 메모리 및 모델 생성을 위해 int 형으로 변환 후 train/test set으로 분할
ratings['user_id'] = ratings['user_id'].astype(int)
ratings['movie_id'] = ratings['movie_id'].astype(int)
train_ratings, test_ratings = split_dataframe(ratings)
train_ratings.shape, test_ratings.shape # ((90000, 3), (10000, 3))
2. Matrix Factorization
이제는 tensorflow를 사용하여 CFModel을 생성해 보도록 하자.
2-1. 모델 생성
user와 movie의 embedding의 차원 수를 30으로 설정하여 각각의 embedding을 만들고 Flatten 함수로 1차원 배열로 변환하여 dot product를 통해 user와 movie가 주어졌을 때 평점을 예측하는 Matrix Factorization 모델을 생성하였다.
users.shape[0], movies.shape[0] # (943, 1682)
# 모델 생성
n_latent_factors = 30 # user와 movie embedding의 차원수
user_input = Input(shape=[1], name='user')
movie_input = Input(shape=[1], name='movie')
user_embedding = Embedding(input_dim=users.shape[0] # 943
, output_dim = n_latent_factors # 30
, name='user_embedding'
)(user_input)
movie_embedding = Embedding(input_dim=movies.shape[0] # 1682
, output_dim = n_latent_factors # 30
, name='movie_embedding'
)(movie_input)
user_vec = Flatten(name='flatten_users')(user_embedding) # 1차원 배열로 변환
movie_vec = Flatten(name='flatten_movies')(movie_embedding) # 1차원 배열로 변환
product = dot([movie_vec, user_vec], axes=1) # 평점
model = Model(inputs=[user_input, movie_input], outputs=product) # user와 movie가 주어졌을 때, 평점을 예측하는 모델
model.summary()
2-2. 모델 학습: Compile, fit
옵티마이저(Optimizer)는 adam으로, loss fucntion(손실 함수)는 MSE로 설정하여 Compile 후 fit 함수를 통해 모델 학습을 진행하였다.
# compile
model.compile(optimizer='adam', loss='mse')
# fit
history = model.fit(x=[train_ratings['user_id'], train_ratings['movie_id']],
y=train_ratings['rating'], epochs=500,
validation_data=([test_ratings['user_id'], test_ratings['movie_id'] ],
test_ratings['rating']),
verbose=1, batch_size=train_ratings.shape[0])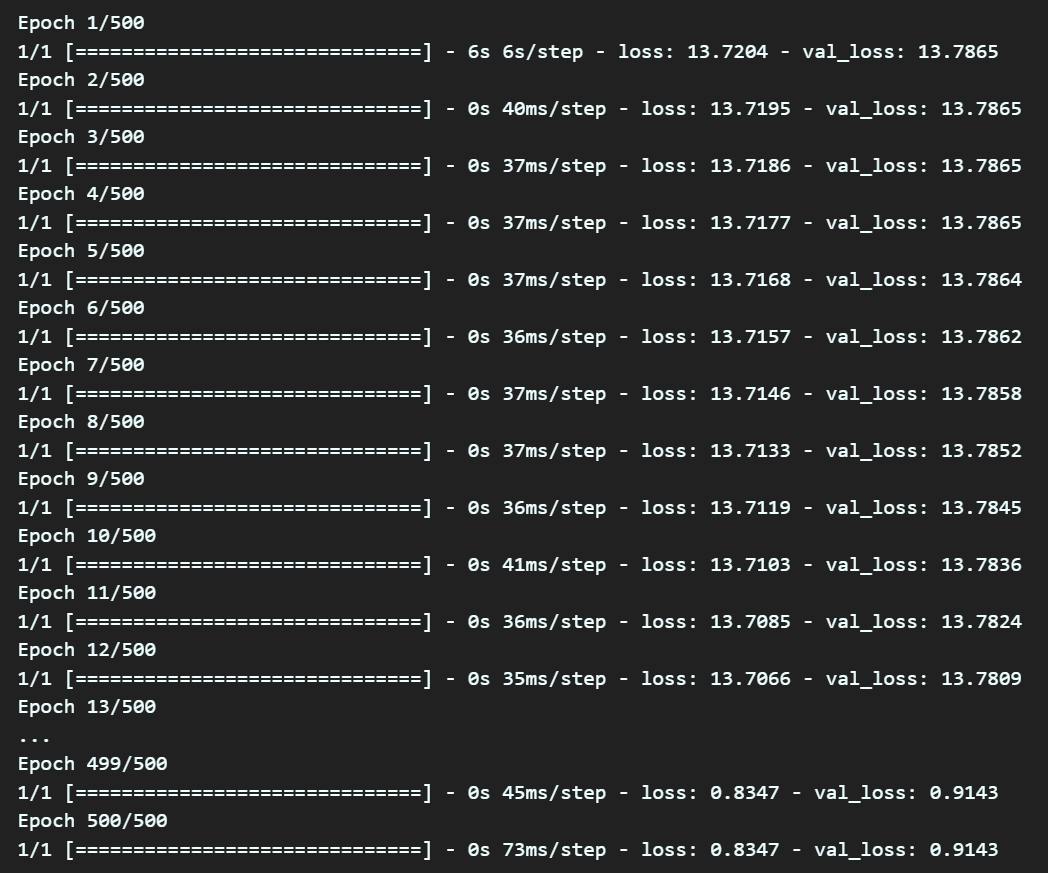
3. 모델 저장
Tensorflow에서 제공하는 save 함수로 모델을 저장했다. 모델을 불러오기 위해서는 Tenseorflow.keras.models에 있는 load_model 함수를 사용하여 불러오면 모델의 구조, 컴파일 정보, 학습된 가중치 모두를 불러올 수 있다.
model.save('CFModel01.h5')
다음 포스팅에서는 이번 포스팅에서 만든 모델을 사용하여 서비스 구현을 해보도록 하겠다.
깃허브에 가시면 모든 코드가 있습니다.
https://github.com/pulpo125/movie_recommendation
GitHub - pulpo125/movie_recommendation
Contribute to pulpo125/movie_recommendation development by creating an account on GitHub.
github.com
팀원: D.heonter
https://ktxdatascience.tistory.com/
k(kim).T(technician).x(express)
ktxdatascience.tistory.com
'프로젝트' 카테고리의 다른 글
| [연재] 개발자 사이드 프로젝트 A to Z 시리즈 소개 (0) | 2025.05.25 |
|---|---|
| (프로젝트)딥러닝_영화 추천 서비스 구현_streamlit을 사용한 서비스구현_화면 구현 (0) | 2023.07.02 |
| (프로젝트)딥러닝_영화 추천 서비스 구현_DB연동_MySQL_Pymysql (0) | 2023.07.01 |
| (프로젝트)Github_VSCode에서 Git으로 협업 하기 (0) | 2023.06.26 |
| (프로젝트)딥러닝_영화 추천 서비스 구현_Overview_협업 필터링이란? (0) | 2023.06.26 |




댓글