
목차
이번 포스팅에서는 드디어 streamlit을 활용해 화면을 구현해보도록 하겠다. 서비스는 유저 등록, 유저 평점 등록, 추천 결과 이렇게 3페이지로 구성되어있으며 페이지가 넘어가는 것을 구현하기 위해 streamlit_js_eval 라이브러리를 사용하였다.
그렇다면, 먼저 첫 페이지인 유저 등록 화면을 만들어보자.
1. 유저 등록 페이지
유저가 입력한 이름, 나이, 성별, 직업 정보를 받아 연동된 DB에 정보를 삽입하는 코드이다. 유저가 모든 정보를 입력하고 '제출' 버튼을 누르면 DB에 정보가 입력되고 자동으로 다음 페이지로 넘어가게 된다.
import streamlit as st
import pandas as pd
import pymysql
import os.path
import pickle as pkle
from streamlit_js_eval import streamlit_js_eval
# mysql 연동
conn = pymysql.connect(host='127.0.0.1'
, port=3306
, user = 'root'
, password='root1234'
, db = 'movie_pj'
, charset='utf8'
)
cursor = conn.cursor()
# multi page 구현
pages=['user','user_rating','recommendation']
if os.path.isfile('next.p'):
next_clicked = pkle.load(open('next.p', 'rb'))
print('next_clicked:', next_clicked)
choice = st.sidebar.radio("Pages",('user','user_rating', 'recommendation'), index=next_clicked)
pkle.dump(pages.index(choice), open('next.p', 'wb'))
#--------------------------------------------------------------------------------------------------#
# user 페이지
if choice=='user':
# header
st.title('환영합니다!')
st.subheader('먼저 당신의 정보를 입력하세요!')
# sign up
# 유저 정보 입력
name=st.text_input("당신의 이름을 입력하세요")
age=st.text_input("당신의 나이를 입력하세요(만나이기준)")
st.write("당신의 성별을 입력하세요")
pick=['M','F']
status=st.radio('성별',pick)
if status==pick[0]: # 남자를 선택했으면 M
sex=pick[0]
elif status==pick[1]: # 여자를 선택했으면 F
sex=pick[1]
oc=st.text_input("당신의 직업을 입력해주세요")
button_state = st.button("제출")
# 제출 버튼을 누르면 DB에 회원정보 등록 및 다음 페이지로 넘어감
if button_state:
sql=f'Insert into users(user_id,age,sex,occupation) values((select max(a.user_id)+1 from users a), {int(age)}, "{sex}", "{oc}");'
cursor.execute(sql)
conn.commit()
st.text('데이터가 반영이 되었습니다. 다음 페이지로 넘어갑니다.')
import time
time.sleep(2)
choice = 'user_rating'
pkle.dump(pages.index(choice), open('next.p', 'wb'))
print('버튼 한 번 클릭')
streamlit_js_eval(js_expressions="parent.window.location.reload()")
2. 유저 영화 평점 등록 페이지
먼저, 유저에게 평점이 많은 Top 50 영화 리스트를 보여주면 유저가 자신이 봤던 영화를 10개 이상 선택하여 각 영화마다 평점을 남기는 서비스를 구현해보도록 하자. 이를 위해, 먼저 평점이 많은 Top 50 영화를 뽑는 함수를 만들어 사용하고 유저가 10개 이상 평점을 남기면 '제출' 버튼이 활성화 되어 다음 페이지로 넘어갈 수 있도록 했다.
2-1. 함수 top_rating 파일 생성
movielens 데이터셋을 넣으면 평점이 많은 순으로 정렬된 Top 50 영화리스트를 반환하는 get_top_idx(), get_top_movies() 함수를 만들어 보자. movielens 데이터셋은 유저 별 영화 rating 정보가 모두 들어있기 때문에, movie_id를 value_counts()하면 평점이 많이 등록된 순서대로 영화별 평점 카운트 결과를 볼 수 있고, 이 결과의 index는 movie_id이기 때문에 .index 함수를 사용하여 평점이 많이 등록된 순서대로 된 movie_id 리스트를 저장하여 Top 50개만 반환하는 get_top_idx() 함수를 만들었다.
또한, movielens 데이터셋과 get_top_idx()의 결과인 top_movie_id를 넣으면 top_movie_id 리스트를 for 루프 문을 통해 돌면서 movielens 데이터셋에서 movie_id로 해당 행을 가져와 title를 반환하여 top_rating_movies 리스트에 append 함수로 영화 제목 정보를 저장하는 함수를 만들었다.
그러므로, 두 함수를 사용하면 평점이 많은 순으로 정렬된 Top 50 영화 제목을 반환 받을 수 있고 우리 팀이 평점이 많은 순으로 50개의 영화를 유저들에게 보여주는 이유는 유저가 영화 평점 정보를 등록할 때 유저들이 아는 영화가 많아야 평점 등록이 수월해지는데, 평점이 많다는 것은 인기있는 영화인 것이고 인기있는 영화이면 모든 사람들이 해당 영화를 봤을 확률이 높기 때문이다.
import pandas as pd
def get_top_idx(movielens):
top_movie_id = list(movielens['movie_id'].value_counts().index)
return top_movie_id[:50]
def get_top_movies(movielens, top_movie_id):
top_rating_movies = []
for idx in top_movie_id:
top_rating_movies.append(movielens.loc[movielens['movie_id'] == idx, 'title'].values[0])
return top_rating_movies
2-2. 유저 영화 평점 등록 streamlit 구현
get_top_idx(), get_top_movies()로 Top 50 영화 제목을 multiselect 로 보여주어 유저가 영화를 선택하면 밑에 영화 마다 평점을 입력할 수 있는 slider bar를 생성하는 코드를 구현했다. rating 범위는 1~5이기 때문에 유저들에게 1~5 사이로 평점을 매겨달라는 문구로 해당 정보를 전달하고, slider bar의 범위는 0~5로 하여 평점 정보를 입력하지 않으면 초깃값인 0인 상태가 되기 때문에, 총 평점 리스트에서 0의 개수를 빼면 유저가 입력한 평점의 개수가 된다. 이를 이용하여, 만약 10개 이상 평점을 매기지 않았다면 '제출' 버튼이 활성화 되지 않고 10개 이상이 되면 제출할 수 있도록 구현했다.
from top_rating import get_top_idx, get_top_movies
# user_rating 페이지
elif choice=='user_rating':
# DB
cursor = conn.cursor()
# movielens table
movielens = pd.read_csv('../data/movielens.csv')
# header
st.title('환영합니다!')
st.subheader('좋아하는 :red[영화]를 선택한 후 :red[평점]을 남겨주세요. :smile:')
# contents
# info
st.write('**1(나쁨)~5(좋음) 사이로 평점을 입력해주세요.**')
st.write("**총 10개 이상의 영화를 평가해야 좋은 추천을 받을 수 있습니다.**")
# 좋아하는 영화 선택
top_movie_id = get_top_idx(movielens)
top_rating_movies = get_top_movies(movielens, top_movie_id)
favorite_movies = st.multiselect('좋아하는 영화를 선택해주세요.', top_rating_movies)
rating_list = []
for i in range(len(favorite_movies)):
rating = st.slider(f'{favorite_movies[i]}의 평점을 입력해주세요.', 0, 5)
rating_list.append(rating)
rating_cnt = len(rating_list) - rating_list.count(0)
if rating_cnt == 0:
btn_state = st.button('제출', disabled=True)
else:
btn_state = st.button('제출', disabled=False)
## db insert
if btn_state:
# user_rating
user_rating_dic = list(zip(top_movie_id, rating_list))
# db ratings 테이블에 insert
for i in range(len(user_rating_dic)):
cursor.execute(f"INSERT INTO ratings (user_id, movie_id, rating) VALUES \
((select max(a.user_id) from users a), {user_rating_dic[i][0]}, {user_rating_dic[i][1]});")
conn.commit()
st.text('데이터가 반영이 되었습니다. 다음 페이지로 넘어갑니다.')
import time
time.sleep(2)
choice = 'recommendation'
pkle.dump(pages.index(choice), open('next.p', 'wb'))
print('버튼 한 번 클릭')
streamlit_js_eval(js_expressions="parent.window.location.reload()")
3. Recommendation 페이지
3-1. recommendation 함수 파일 생성
전 포스팅에서 만들었던 model 을 넣으면 추천 결과를 보여주는 코드이다. 해당 코드는 구글의 머신러닝 추천 시스템 교육 파일에서 참고했으며, 원래 코드는 cosine similarity, dot product 별로 결과를 볼 수 있게 하지만 이번 프로젝트에서는 dot product 만을 사용하여 유저들에게 인기있는 영화 위주로 추천하기로 결정했기 때문에 dot product만을 구현하였다.
우리가 인기있는 영화 위주로 추천하기로 결정한 이유는, 이번 프로젝트가 유저가 처음 서비스를 등록했을 때 추천 결과를 보여주는 것 이므로 인기있는 영화들이 처음 들어온 유저들에겐 흥미롭게 느껴질 수 있다고 생각했기 때문이다.
import pandas as pd
def compute_scores(query_embedding, item_embeddings):
u = query_embedding
V = item_embeddings
scores = u.dot(V.T)
return scores
# User recommendations and nearest neighbors
def user_recommendations(model, movies, ratings, exclude_rated=False, k=6, user_id=570):
USER_RATINGS = True
if USER_RATINGS:
scores = compute_scores(
model.embeddings["user_id"][user_id], model.embeddings["movie_id"])
score_key = 'dot' + ' score'
df = pd.DataFrame({
score_key: list(scores),
'movie_id': movies['movie_id'],
'titles': movies['title'],
'genres': movies['all_genres'],
})
if exclude_rated:
# remove movies that are already rated
rated_movies = ratings[ratings.user_id == str(user_id)]["movie_id"].values
df = df[df.movie_id.apply(lambda movie_id: movie_id not in rated_movies)]
return (df.sort_values([score_key], ascending=False).head(k))
3-2. Recommendation 결과 페이지 Streamlit 구현
전 페이지에서 등록된 user_id를 불러와서 먼저, 해당 user_id와 비슷한 유저의 추천 결과를 보여주고, 향후 데이터가 많이 쌓이면 해당 데이터셋으로 모델을 업데이트(재학습)하여 유저에게 fit한 추천 결과를 보여주기로 결정했다.
비슷한 유저를 찾는 것은 신규 유저의 평점 정보 까지 업데이트 된 ratings 테이블에서 데이터를 가져와 cosine_similarity 로 가장 비슷한 유저 한 명을 선택하도록 했다.
또한, 전 포스팅에서 생성했던 model을 load_model 함수로 불러와 추천 결과를 보여주게 했으며, load_model 함수 사용시 오류가 처음에 있었는데 코랩에서 해당 모델을 학습할 때의 tensorflow 버전과 현재 내가 작업하고 있는 VSCode 의 tensorflow 버전이 달라서 compile=False를 추가하여 컴파일 정보를 불러오지 않으면 해당 에러를 해결할 수 있었다.
마지막으로, 밑에 코드는 임의로 유저와 평점 정보를 등록해보고 그 데이터로 다시 모델을 재학습 시킨 CFModel2를 적용한 코드이다.
from recommendation import compute_scores, user_recommendations
import tensorflow as tf
from sklearn.metrics.pairwise import cosine_similarity
# recommendation 페이지
elif choice=='recommendation':
# Data Load
movies_sql = 'SELECT * FROM movies'
movies = pd.read_sql(movies_sql, conn)
ratings_sql = 'SELECT * FROM ratings'
ratings = pd.read_sql(ratings_sql, conn)
# user_id
cursor = conn.cursor()
cursor.execute('select max(a.user_id) from users a')
idx = cursor.fetchall()
user_id = idx[0][0]
# similar
pvt=ratings.pivot_table(index='user_id',columns='movie_id',values='rating').fillna(0)
cos_sim=cosine_similarity(pvt,pvt)
cos_sim_df=pd.DataFrame(data=cos_sim)
similar_user_id = cos_sim_df[user_id].sort_values(ascending=False).index[1]
# CFModel
CFModel02 = tf.keras.models.load_model('../data/CFModel02.h5', compile=False)
CFModel02.embeddings = {
'user_id': CFModel03.get_layer('user_embedding').weights[0].numpy(), # U
'movie_id': CFModel03.get_layer('movie_embedding').weights[0].numpy() # V
}
# recommendation
st.title('추천 결과입니다. :smile:')
similar_result = user_recommendations(CFModel02, movies, ratings, k=10, user_id=similar_user_id, exclude_rated=True)
st.write(f'유사한 유저 결과: {similar_user_id}')
st.dataframe(similar_result)
user_result = user_recommendations(CFModel02, movies, ratings, k=10, user_id=user_id, exclude_rated=True)
st.write(f'유저 결과: {user_id}')
st.dataframe(user_result)
conn.commit()
conn.close()
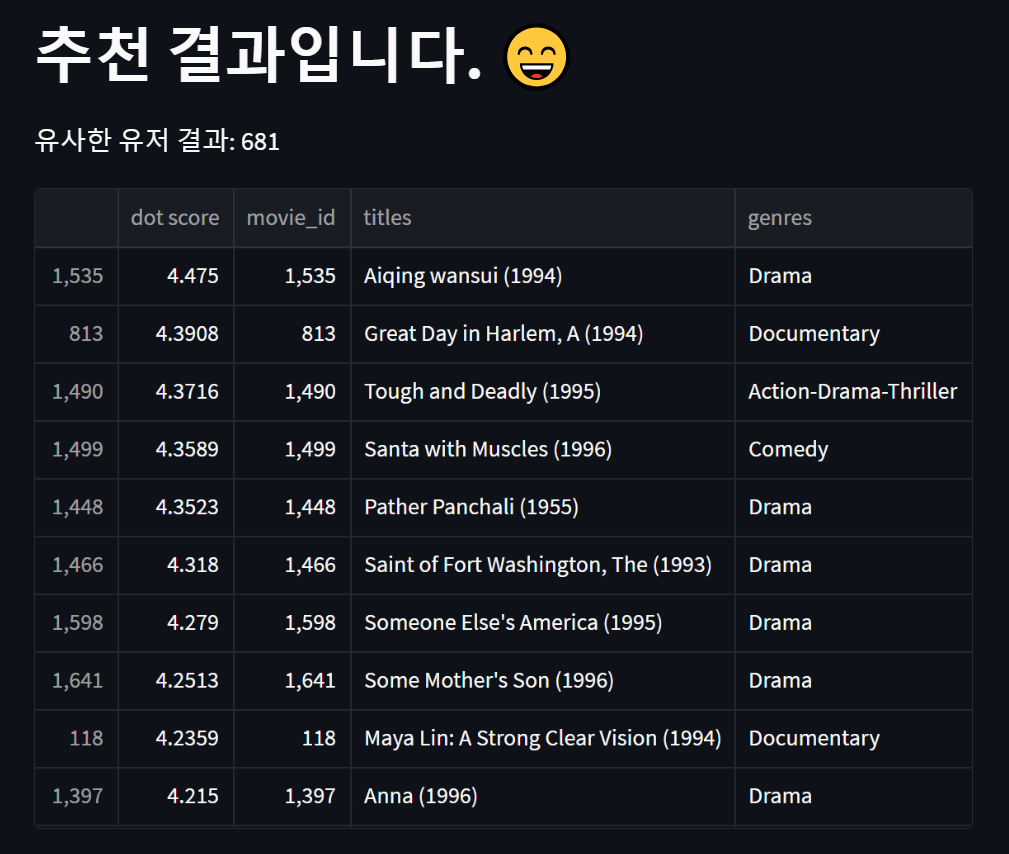
예를 들어, 지금 등록한 유저 id가 942 일 때, cosine similarity 결과 681번 유저가 가장 유사하기 때문에 해당 유저의 결과를 보여주고 데이터가 쌓여 모델을 업데이트 하게 되면 신규로 등록된 유저 942번의 데이터도 해당 모델에 들어가기 때문에 그 유저의 추천 결과를 보여줄 수 있는 것 이다. 밑에 사진은 그 결과물로, 두 유저의 추천 결과가 매우 유사함을 볼 수 있다.

깃허브에 가시면 모든 코드가 있습니다.
https://github.com/pulpo125/movie_recommendation
GitHub - pulpo125/movie_recommendation
Contribute to pulpo125/movie_recommendation development by creating an account on GitHub.
github.com
팀원: D.heonter
https://ktxdatascience.tistory.com/
k(kim).T(technician).x(express)
ktxdatascience.tistory.com
'프로젝트' 카테고리의 다른 글
| (프로젝트)딥러닝_영화 추천 서비스 구현_streamlit을 사용한 서비스구현_CFModel 만들기_Matrix Factorization (0) | 2023.07.01 |
|---|---|
| (프로젝트)딥러닝_영화 추천 서비스 구현_DB연동_MySQL_Pymysql (0) | 2023.07.01 |
| (프로젝트)Github_VSCode에서 Git으로 협업 하기 (0) | 2023.06.26 |
| (프로젝트)딥러닝_영화 추천 서비스 구현_Overview_협업 필터링이란? (0) | 2023.06.26 |
| (프로젝트)머신러닝_Netflix 영화 데이터셋을 이용한 '협업 필터링' + '콘텐츠 기반 필터링' 영화 추천_3) 추천 시스템 개발 (0) | 2023.06.25 |




댓글